How an AI identity verification startup used NVIDIA TensorRT, Nsight DL Designer, TAO, and the NGC Catalog to achieve 10x inference speedup, and what that unlocked for real-time deepfake detection.
TL;DR
- Validit.ai built a real-time AI pipeline for deepfake detection and human authenticity verification in real-time sessions.
- Joining the NVIDIA Inception program gave access to tools, pre-trained models, and expert guidance that transformed the system performance.
- Using NVIDIA Nsight DL Designer, inference time on edge devices dropped by 20%, enabling support for a wider range of low-spec hardware.
- Using the NVIDIA NGC ConvNeXtV2 model via TAO Toolkit, feature extraction throughput increased 4x on the same hardware.
- Using the NVIDIA TensorRT SDK, inference time dropped from 113 ms to 12 ms, a 10x speedup.
- Using the NVIDIA ReIdentificationNet from NGC, a second-opinion ensemble model was deployed, improving precision without additional model development.
- Total business impact: lower cloud costs, faster time to market, broader device support, and a more reliable, scalable AI system.
Introduction: The Trust Problem AI Must Solve
The world has a deepfake problem. In 2024, AI-generated synthetic identities and manipulated video became sophisticated enough to fool not just humans, but many automated verification systems. Financial services, government agencies, and high-security enterprises are dealing with an escalating fraud landscape where the question “Is this a real person?” can no longer be answered with a simple ID check.
Validit.ai was founded to solve exactly this problem. Our mission: “Verifying who’s real and what’s true, in real time, when it matters most.” We build AI systems that evaluate live video sessions to verify human identity and assess the authenticity of assertions made in that session, in real time, without compromising user experience.
The problem is technically brutal. Our pipeline must run on cloud servers and on low-spec edge devices in emerging markets. It must detect face swaps, liveness attacks, and deepfakes simultaneously. It must operate in under 100 milliseconds per frame to feel seamless, at the scale of concurrent enterprise deployments. Early on, it became clear that standard inference pipelines could not meet these requirements.
The turning point was joining the NVIDIA Inception program for startups. As part of the program, we accessed NVIDIA’s full optimization stack, including TensorRT, Nsight Deep Learning Designer, TAO Toolkit, and the NGC Catalog, along with direct guidance from NVIDIA’s deep learning engineers. The results: primary inference latency from 113 ms to 12 ms in our cloud pipeline, 4x increase in cloud throughput in another cloud pipeline, and a 20% reduction in edge-device runtime. This post tells that story.
The Challenge: Why Real-Time Human Authenticity Is Hard
Before diving into NVIDIA tools, it is worth understanding why this problem is technically demanding. Identity fraud is not a simple binary problem. It exists across a spectrum of attack types, each requiring its own detection approach.
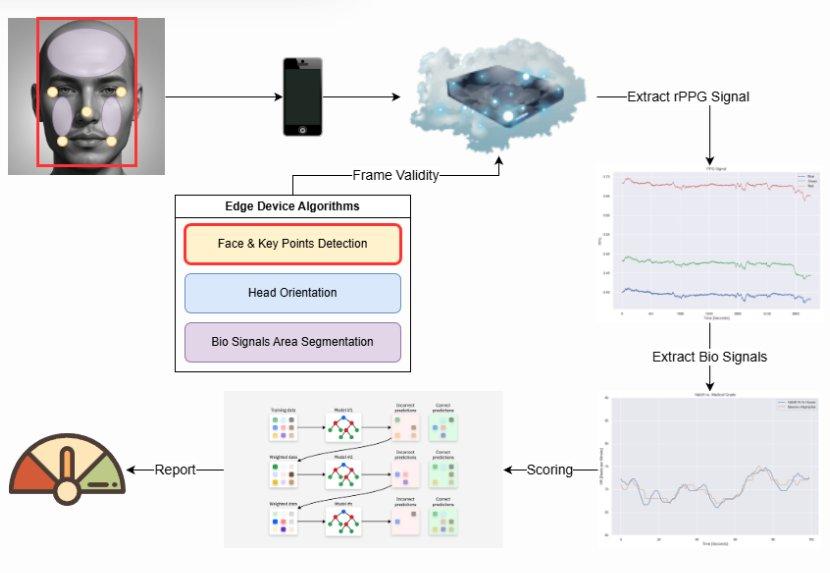
Validit.ai: real-time session pipeline from edge device to cloud scoring
At the low end, an attacker might use a printed photo held up to a camera. In the middle, they might replay a pre-recorded video. At the high end, and this is where the problem gets genuinely hard, they use real-time deepfake technology: live AI-generated faces that mimic a target identity in real time, responding dynamically to instructions. These tools are no longer confined to well-resourced attackers; they are increasingly accessible.
Our use case makes this harder still. A Validit.ai session is a structured live interaction: the person under test answers a predefined set of yes/no questions while our system simultaneously records physiological signals, to assess the reliability of their answers. The system must verify authentic human presence and evaluate credibility, in real time, across an unreliable network connection from a potentially low-spec device. Every millisecond of latency matters.
Our initial inference pipeline simply could not run fast enough to meet these constraints without compromising accuracy or scalability. We needed a fundamentally more efficient approach. The NVIDIA Inception program helped us develop the roadmap to get there.
Our Architecture: Balancing Edge and Cloud with NVIDIA
Validit.ai’s system is built around three layers, each with distinct performance constraints. From the beginning, we designed with NVIDIA’s optimization stack in mind, because the tools available to us shaped what was architecturally possible.
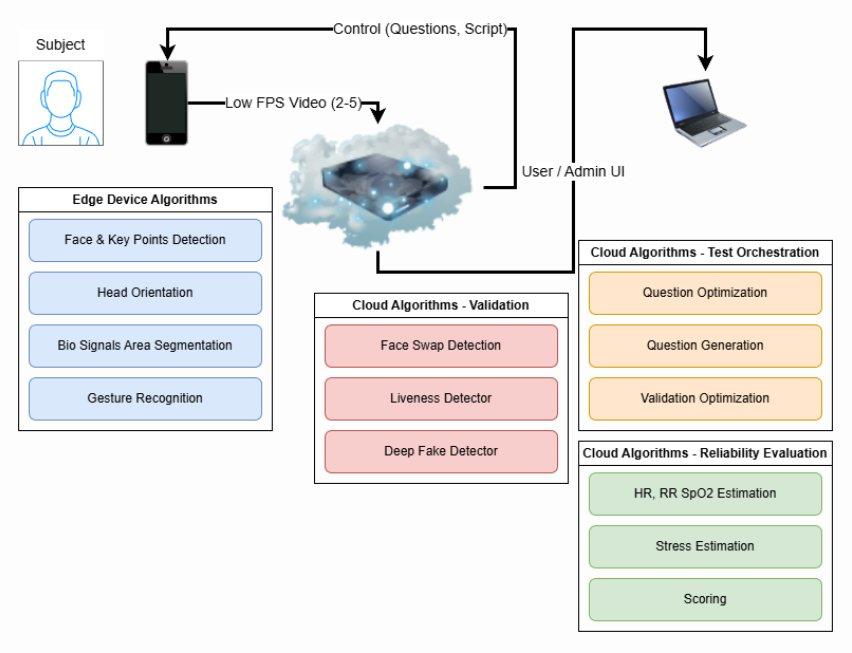
Validit.ai system architecture: Edge Device algorithms, Cloud Validation, and Cloud Reliability Evaluation
The Edge Device Layer
The edge device is whatever the user has: a laptop, a smartphone, or a low-end tablet. It runs our web application, handles face-pose validation, and extracts the raw data needed to compute Biosignals. Critically, it must do this with minimal hardware resources, as we target customers in markets where broadband is unreliable and processing power is limited.
NVIDIA tools played a key role here through NVIDIA Nsight Deep Learning Designer, which we used to optimize our edge model’s computational graph and export it in ONNX format. Though Nsight DL Designer is primarily associated with TensorRT targets, it is also effective for ONNX optimization, which is our deployment format for edge environments that may not have NVIDIA GPUs. More on this in Use Case 1.
The Backend Layer
The backend is where the heavy AI work happens. It orchestrates the test, validates the subject’s identity, runs deepfake detection, and scores the reliability of the session. This is the layer where NVIDIA TensorRT had its most dramatic impact. It is NVIDIA’s inference SDK and runtime, which compiles and optimizes model computational graphs for NVIDIA GPU hardware through layer fusion, precision calibration, and quantization. Deploying our primary inference model with TensorRT reduced per-frame latency from 113 ms to 12 ms.
The Frontend Layer
The frontend is the Validit.ai application that the customer uses: it configures the test questions, structures the session, and presents results. From an AI perspective, it is the orchestration layer that ties edge and backend together, passing signals and responses in real time.
The architecture deliberately minimizes bandwidth requirements by handling as much as possible at the edge, and only transmitting compressed signal data to the backend. This design was only viable because NVIDIA’s optimization tools allowed us to fit meaningful AI workloads onto edge devices that we previously could not support.
Our Algorithms: Proprietary Models Built for an Unsolved Problem
There is no off-the-shelf model for what Validit.ai does. Assessing the credibility of a live human assertion, while simultaneously verifying identity and detecting deepfakes in real time, is a use case that we had to build from the ground up. Our models were developed for three reasons:
- Hardware optimization: We needed a detection model with less than 300,000 parameters to run on edge devices without sacrificing detection quality.
- Cost optimization: We took known architectures and aggressively tuned them for throughput and latency, with NVIDIA tools providing the optimization layer.
- Unique use case: No existing model covers Biosignal-based reliability scoring combined with real-time liveness and deepfake detection. We built and patented the approach.
Face Swap Detection
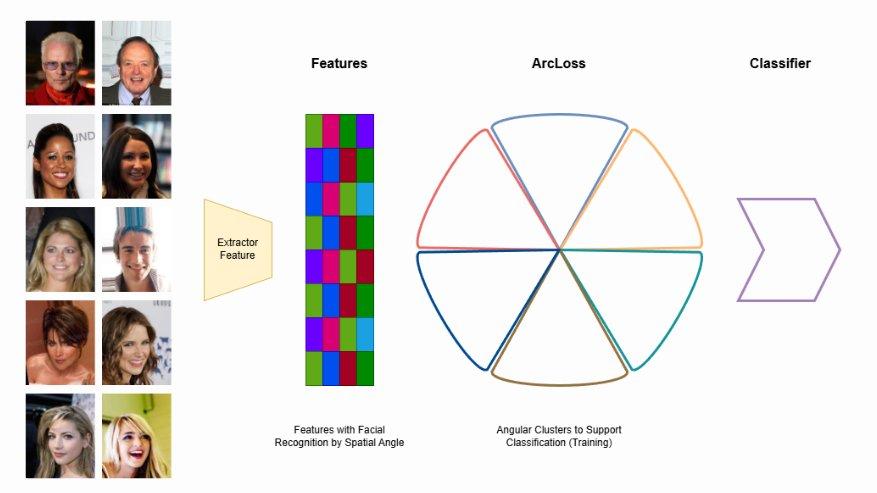
ArcLoss-based face recognition: feature extraction, ArcLoss embedding, and classifier
The first thing our system verifies is that the same person appears throughout the session. A simple face match at the beginning is not enough, as an attacker might swap identities mid-session. We need continuous verification across every frame.
Our face recognition model is based on the ArcFace approach. Rather than using Triplet Loss, which requires large, carefully curated datasets and fragile training, we use a feature extractor that projects embeddings onto a unit sphere, combined with an ArcLoss-based classifier that groups the same face into the same region. During inference, we compare embeddings frame-by-frame using cosine similarity. This architecture lets us train on standard labeled-face datasets, which are far easier to source and annotate.
We later augmented this model with the NVIDIA NGC ReIdentificationNet, fine-tuned via TAO, as a second-opinion ensemble. The combination improved precision without requiring us to build a second model from scratch.
Fraud Detection (Liveness Testing)

Fraud and liveness detection: classifying presentation attack types
Liveness testing is the detection of presentation attacks: printed photos, replayed videos, or video injection. Our classifier is fine-tuned for our specific scenario and must achieve near-perfect precision with high recall while remaining efficient enough to run in real time alongside the rest of the pipeline. Training data combines publicly available datasets with our own annotated collection, giving us specificity to the types of attacks we encounter in production.
Deepfake Detection
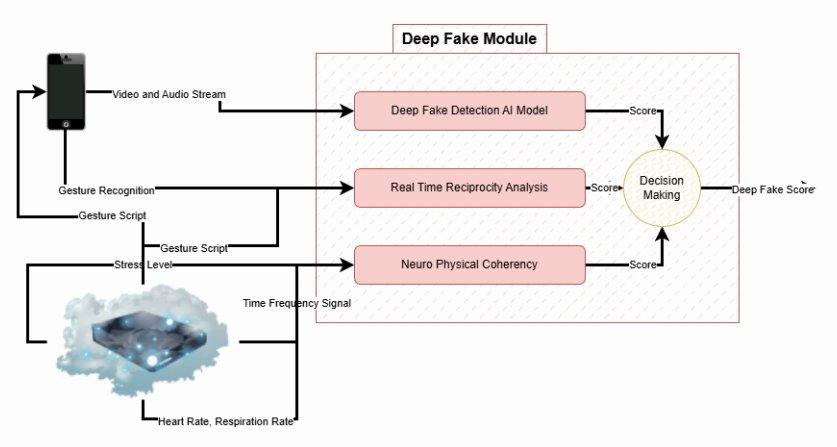
Deepfake detection module: biosignal analysis, real-time reciprocity, and decision making
Deepfake detection is the hardest part of the problem, and where our approach is most differentiated. AI-generated synthetic faces have improved to the point where single-frame analysis alone is no longer reliable. We developed a patent-pending approach that combines two proprietary capabilities that most competitors lack:
- Proprietary Biosignal extraction: We extract physiological signals, subtle real signals from the human body, that cannot be trivially synthesized by even the most advanced generative AI systems. A real person has a heartbeat, micro-expressions, and involuntary physiological responses.
- Real-time bidirectional challenge: We instruct the subject to perform specific actions during the session that we can independently verify. This prevents pre-recorded or generative attacks, you cannot replay a video that responds dynamically to instructions issued in real time.
This combination gives us an edge over single-signal detection methods and extends, to some degree, to non real-time scenarios as well. Paired with open-source base models, it delivers a better recall and precision than any other solution we have tested internally on our use cases and datasets.
The NVIDIA Technology Stack: Tools That Extended Our Market Reach and Reduced Inference Costs
The NVIDIA Inception program for startups gave Validit.ai more than technology resources . It connected us to the AI ecosystem , along with guidance from NVIDIA’s deep learning engineers. Understanding the role of each tool is important, because they serve distinct and complementary purposes.
NVIDIA NGC Catalog
The NVIDIA NGC Catalog is a library of deployment-optimized pre-trained models. For Validit.ai, it removed months of development time by giving us strong starting points for both our feature extraction and re-identification models. NGC models are designed to be fine-tuned using the TAO framework, which is exactly how we used them.
NVIDIA TAO Toolkit
The NVIDIA TAO Toolkit (Train, Adapt, and Optimize) is a CLI-based framework for fine-tuning NGC models on custom datasets without writing training code from scratch. For us, TAO meant we could take the NGC ConvNeXtV2 and ReIdentificationNet models and adapt them to Validit.ai’s specific data distribution quickly and reproducibly.
NVIDIA TensorRT SDK
NVIDIA TensorRT is NVIDIA’s inference SDK and runtime. It works programmatically to optimize a model’s computational graph: layer fusion, precision calibration/quantization (FP16 / INT8 / etc…), kernel selection, and compiling the result into a TensorRT engine optimized for a specific GPU. PyTorch users can access TensorRT through Torch-TensorRT, either via torch.compile() or ahead-of-time export via torch.export(). This is the tool that took our primary inference from 113 ms to 12 ms per frame.
NVIDIA Nsight Deep Learning Designer
Where TensorRT is the programmatic runtime, NVIDIA Nsight Deep Learning Designer is the UI-based tool for visualizing and optimizing model computational graphs. It lets engineers see the graph structure, identify bottlenecks layer by layer, and iterate on optimizations. Importantly, while it is primarily used to generate TensorRT targets, it also supports ONNX model optimization, which was how we used it for our edge device model, where NVIDIA GPUs may not be present at deployment time. That changed what was possible and made the edge model fit the minimum frame-rate target on lower-spec devices. The exported optimized ONNX models were tested with ONNX Runtime Web on various edge devices: Samsung Galaxy S Series, Samsung Galaxy A Series, Apple iPhone, Apple iPhone Pro, OnePlus Nord, Nothing Phone, Xiaomi Poco, Apple iPad, Apple iPad Pro, Samsung Galaxy Tab S Series, Samsung Galaxy Tab A Series from the last 2-3 years with Safari and Chrome browsers.
Four Use Cases That Transformed the Product
The following use cases represent our most significant engineering milestones with NVIDIA technology. Each one began with a concrete bottleneck and ended with a measurable improvement that directly affected what Validit.ai could offer to customers.
Use Case 1: Optimizing the Edge Device Model
Our first challenge was the edge model. To serve customers in emerging markets, we needed to run real-time object detection, keypoint detection, and image segmentation on consumer-grade hardware with no NVIDIA GPU. We built a custom architecture with under 300,000 parameters. We used NVIDIA Nsight Deep Learning Designer to visualize the model’s computational graph, identify bottlenecks, and generate an optimized ONNX export for deployment.
The result: A 20% reduction in inference time on low-spec edge devices, expanding the pool of supported hardware and directly growing the addressable customer base in emerging markets.
| Base Model | Optimized Model | HW | Batch Size | Effect |
| Self-Made Architecture | Optimized with NVIDIA Nsight Deep Learning Designer | Edge Device, ONNX Run Time for JS | 1 | 20% higher FPS on average on our hardware set |
Use Case 2: Accelerating the Feature Extraction Model
Rather than training a feature extractor from scratch, we adopted the NVIDIA NGC pretrained ConvNeXtV2 model. We fine-tuned it on our proprietary dataset using the NVIDIA TAO Toolkit, and deployed it with TensorRT for production inference. It replaced a vanilla implementation of the ConvNext model.
The result: A 4x increase in cloud inference throughput on the same hardware, plus a shift to weekly fine-tuning updates, keeping our models current with real-world conditions.
| Base Model | Optimized Model | HW | Batch Size | Effect |
| Vanilla PyTorch ConvNext | NGC ConvNeXtV2 | Cloud VM with NVIDIA L4 / NVIDIA T4 GPU | 1 | X4 Inference, no quality deterioration |
Use Case 3: 10x Inference Speedup with TensorRT
Our primary cloud model, a ViT based model, was running at 113 ms per frame at deployment. Using the NVIDIA TensorRT SDK, we optimized the model’s computational graph through layer fusion and INT8 precision calibration, compiling it to a TensorRT engine for our cloud GPU environment.
The result: Inference time dropped from 113 ms to 12 ms per frame, a 10x speedup. This translated directly into a cost structure change: 10x more concurrent sessions per GPU instance, with the option to downsize cloud infrastructure and reduce cost per session significantly.
| Base Model | Optimized Model | HW | Batch Size | Effect |
| ViT Based | Optimized for cloud inference with NVIDIA TensorRT SDK | Cloud VM with NVIDIA L4 / NVIDIA T4 GPU | 1 | 10 times higher throughput |
Use Case 4: Ensemble Re-Identification Model from NGC
We fine-tuned the NVIDIA ReIdentificationNet from the NGC Catalog using TAO, deploying it as a real-time second-opinion model alongside our primary face recognition model.
It worked quite well on face recognition using face crops out of the box. The finetuning process improved the precision results on our own dataset by 3% more.
The result: A production-ready ensemble improving overall precision, which is critical where false positives carry real consequences for the user. It also significantly accelerated ground-truth dataset labeling during development.
Results at a Glance
| # | Use Case | NVIDIA Tool | Result | Business Benefit |
| 1 | Small vision model (CNN) optimization | NVIDIA Nsight DL Designer (ONNX export) | 20% inference time reduction on edge | Broader device support, higher frame rates |
| 2 | Vision feature extraction model | NGC ConvNeXtV2 via NVIDIA TAO | 4x cloud throughput increase | Lower cloud costs, weekly fine-tuning cycles |
| 3 | Cloud inference deployment | NVIDIA TensorRT SDK and runtime | 113 ms to 12 ms (10x speedup) | 10x more concurrent sessions, major cost reduction |
| 4 | Human Re-ID ensemble model | NGC ReIdentificationNet fine-tuned via TAO | Production-ready second-opinion model | Higher precision, faster ground-truth labeling |
Business Impact: What 10x Inference Speedup Means for a Startup
Performance numbers are meaningful, but what they unlocked for Validit.ai as a business is the real story. The NVIDIA Inception p rogram and AI stack delivered impact across four dimensions that directly shaped our commercial trajectory.
Time to Market
Before NGC and TAO, building a new model meant starting from scratch: gathering data, defining architecture, and iterating for weeks. With NGC pre-trained models and TAO fine-tuning, we could go from idea to production deployment in a fraction of the time, meaning faster product iterations and faster customer feedback.
Higher Throughput and Lower Cloud Costs
The TensorRT optimization translated directly into unit economics. We process 10x more frames per GPU per second. We used this headroom either to support more concurrent users on the same infrastructure, or to downsize cloud instances and reduce cost per session.
Wider Customer Reach
The edge model optimization via Nsight DL Designer was a market expansion story. A broader set of lower-spec devices crossed our performance threshold after optimization. For a company targeting customers in markets where a standard device is a mid-range smartphone from three years ago, every device tier we support is additional addressable market.
Access to Deep Learning Expertise
NVIDIA’s engineers walked through our specific use cases, identified optimization opportunities we had not considered, and shared knowledge from similar problems they had seen. For a small AI team, this kind of direct expert access is extraordinarily valuable.
Conclusion: What NVIDIA Enabled for Validit.ai
Validit.ai’s mission, verifying human authenticity in real time, is one of the hardest applied AI problems we know of. It requires combining computer vision, biosignal analysis, liveness detection, and deepfake detection into a single pipeline that runs fast enough to feel seamless to the user, at the scale of enterprise deployments, across wildly different hardware environments.
NVIDIA technology gave us the tools to get there. TensorRT delivered the 10x inference speedup that changed our cost structure. Nsight Deep Learning Designer gave us visibility into our model graphs to make targeted optimizations. TAO and the NGC Catalog removed months of model development work and gave us strong baselines to build from. And NVIDIA’s engineers gave us the knowledge to use all of it well.
For any AI startup working on real-time inference with tight latency and cost constraints, particularly one operating across cloud and edge environments, we strongly recommend exploring the NVIDIA Inception Program and the tools available through it. For Validit.ai, it made a big difference.